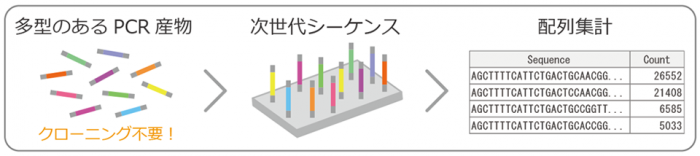
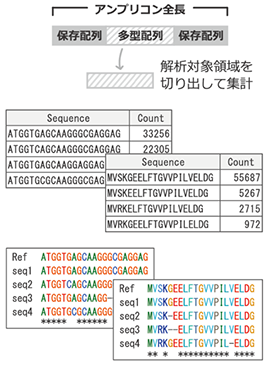
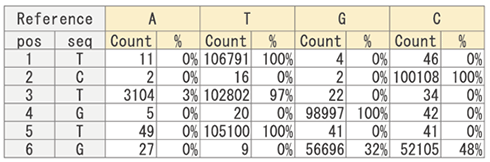
ターゲット遺伝子領域を深く解析するAmplicon NGS
| シーケンサー | NovaSeq | MiSeq |
|---|---|---|
| 読み取り方法 | Paired-End 150bp x 2 | Paired-End 300bp x 2 |
| データ取得量の単位 | 330万リードペア(1Gb) / 検体~ | 10万リードペア(60Mb) / 検体~ |
| 推奨インサートサイズ (対応可能インサートサイズ) | 200bp~250bp(約20 bp~約800bp) | 250bp~450bp(約 20bp~約800bp ) |
| PCR産物(インサート) サイズについて |
PCR産物サイズが推奨インサートサイズの範囲外であってもシーケンスは可能です。ただし、データ量保証の対象外とさせていただく場合がございますので、推奨範囲から大きく異なる場合は事前にご相談ください。 推奨インサートサイズよりも大きいPCR産物の場合、リード後半部のQV低下によりRead1/Read2のオーバラップが取り難くなります。Amplicon-SeqではRead1/Read2のオーバーラップを取ることでアンプリコン全長の配列を決定するため、解析上の有効リード数が減少しますのでご注意ください。 |
|
* インサートサイズ = 1st PCRで得られるPCR産物のサイズからリンカー配列を除いたサイズを指します。
リンカー配列の長さは、FW・RVを合計して67bpとなります。
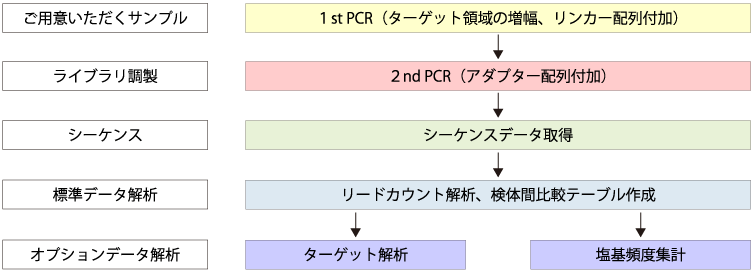
以下のファイルをご利用の上、お問い合わせフォーム からご送付ください。
| サービス項目 | 価格(税抜) | 納期 |
|---|---|---|
| 次世代シーケンス Illuminaアンプリコンシーケンス解析 | お問い合わせ | お問い合わせ |
/
※お問い合わせは完了しておりません。